Christopher Szeliga
CHRISTOPHER SZELIGA
BACKEND SOFTWARE
ENGINEER @ ![]()
Z DEEP LEARNING COMPILER
Undergraduate
Teaching
Assistant

I worked as an Undergraduate Teaching Assistant for a 120-student Advanced Data Structures course (CS 351), supporting both professors and graduate TAs. Throughout the semester, I helped students understand and implement a wide range of topics, including linked lists, maps, skip lists, Huffman encoding, balanced trees (AVL, Red-Black, B-Trees), splay trees, heaps (binary, binomial, Fibonacci), tries, suffix arrays/trees, disjoint sets, Bloom filters, cuckoo hashing, XOR filters, and graph algorithms.
In addition to answering questions on Piazza throughout the week, I attended every lecture to assist with the in-class practice drills, debug code in real time, and guide students through whiteboard-style explanations of algorithms and data structure operations. I also served as the project manager for multiple full-stack student group projects, offering code reviews and feedback, providing architectural and technical guidance, ensuring correct use of advanced data structures in their backend logic, and grading each milestone of their semester-long project.

2D LATTICE BOLTZMANN METHOD SIMULATION
FOR COMPUTIONAL
FLUID DYNAMICS
SPEEDUP
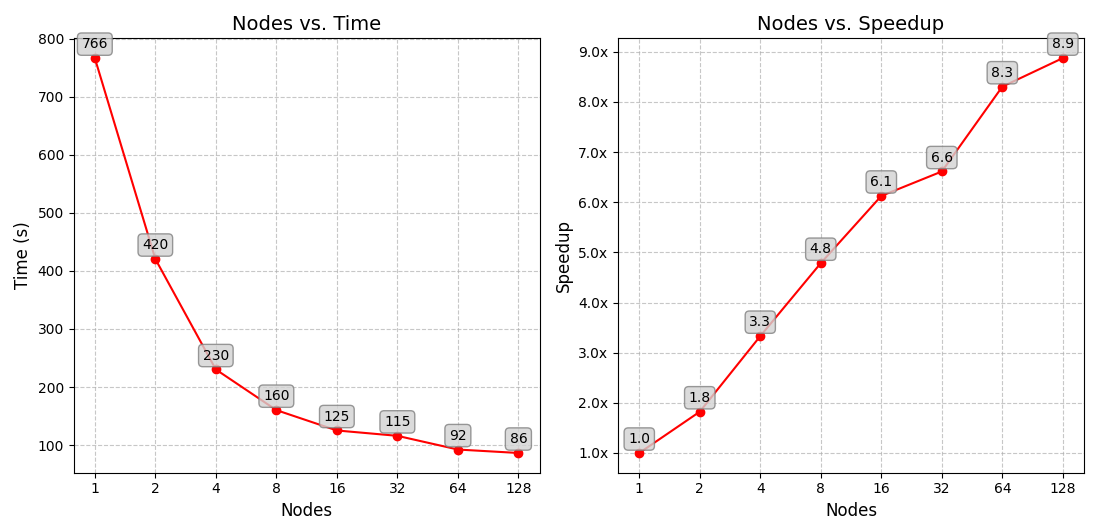
I developed and optimized a C++ Lattice Boltzmann Method (LBM) fluid simulation focused on high-performance computing and parallel processing. I used OpenMP to parallelize the most compute-heavy parts of the code, achieving up to a 7.8× speedup with 8 threads. I also scaled the simulation across multiple machines using MPI on Argonne National Laboratory’s Crux supercomputer and UIC’s Lakeshore HPC cluster, reaching a 3.3× speedup on 4 nodes. To handle communication between distributed parts of the simulation, I implemented a ghost row technique to exchange boundary data between neighboring nodes at each timestep. I also used Python, Pandas, and Matplotlib to visualize the results and analyze how the simulation performed and scaled.
YET ANOTHER
LARGE
LANGUAGE
MODEL
I developed a distributed end-to-end language modeling pipeline in Scala called Yet Another LLM, built to explore how large-scale language models are put together across data processing, training, and deployment. The project starts with a Hadoop MapReduce-based ETL pipeline that processes large text corpora by sharding datasets, tokenizing text, computing token frequencies, and generating Word2Vec embeddings using DeepLearning4j for scalable preprocessing. This stage was designed to handle large volumes of data efficiently while distributing work across multiple nodes. The generated embeddings are then fed into a Spark-based training pipeline that uses sliding-window techniques to create context-aware training samples and train a neural language model across distributed AWS infrastructure. By distributing the training process, the system can process larger datasets more efficiently while improving throughput and reducing preprocessing bottlenecks. Finally, I deployed the project as a production-style inference service using an Akka HTTP server on EC2, routing requests through API Gateway and AWS Lambda to Amazon Bedrock’s Command R model for scalable real-time text generation.